Stable Diffusion webui(AUTOMATIC1111版)の導入解説
先日、諸事情からStable Diffusion web UIの環境を再構築しました。
といっても、pythonとかは最初に構築したときにインストール済みなので、webuiの再構築部分だけでしたが。
そして、ある程度ファイル構造を理解してからやってみた再構築は、思っていた以上に簡単で低工数でできるものでしたので、ひとまず2023年1月1日現在で通用する、Stable Diffusion web UIの構築手順を記載しておくことにしました。
Stable Diffusion web UI(AUTOMATIC1111版)
ローカル環境で動作するStable Diffusionです。
AIによる画像構築にグラフィックボードを使うため、ゲーミングPCでの構築を推奨します。
NovelAIやHolaraはオンラインで動作し、自分PCの環境を問わない代わりに有償ですが、ローカルなら自分PCの環境次第な代わりに、画像を何千枚出力しても無料です。
個人的に、今のAI絵のレベルならPCを買い直してまでやる、というものではないと思っています。
どの絵も顔まわりは綺麗でも、手や足、ポーズ全体で見るとどこかしら溶けてたりするしね。
一方で、ちょうどPCを買い替えようと思っていたぞAI絵にも興味があるぞ、という人は、それを前提にスペックを決めても良いでしょう。
AI絵でお目当ての画像が出るまで、ひたすらガチャを繰り返す楽しさも間違いないものですよ。
なおWindowsを前提にしています。
環境の確認
まずPCスペックについては「これだけあればOK」というのが難しいです。
遅くても動作すればいいのか、スムーズに動かすことを前提にしたいのか…また、私は自分の持っているPCでの動作しか知りませんので「このスペックならどうか」というのも答えられません。
ので、以下は1例として、私のPCスペックになります。
| CPU | インテル Core i7-11700 |
|---|---|
| グラボ | GeForce RTX 3070(VRAM 8GB) |
| メモリ | 16GB |

このスペックで、この512×512・Step20の絵1枚に3秒くらいです。

ちなみに1024×1024・Step20にすると14秒くらいになります。
縦横は2倍ですが、つまり面積は4倍なのでまぁ妥当なくらいの時間。

さらにちなみに、1024×1024・Step60にすると35秒くらいでした。
快適な画像生成が出来ておりますので、参考にどうぞ。
では、以下インストールの手順です。
pythonのインストール
pythonでパイソンと読む、プログラミング言語です。
オープンソースで運営されていますので、無料でダウンロードが可能です。
webuiの動作には必要なので、インストールしましょう。
ダウンロードは公式HPであるhttps://www.python.org/から。
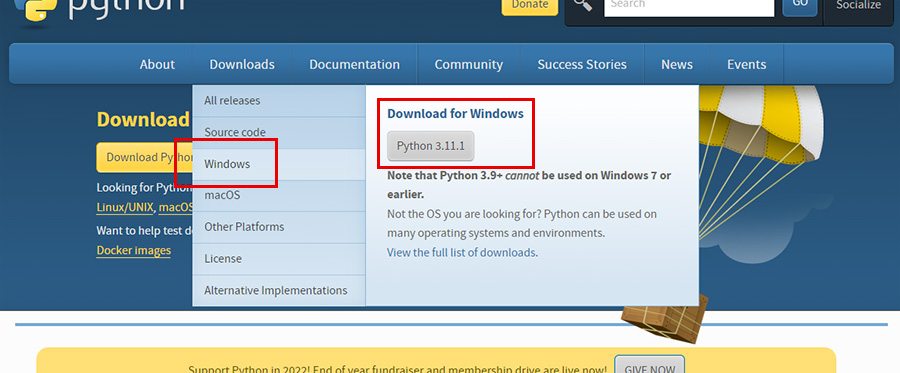
青いメニューバーの「Downloads」にカーソルを載せると、「Download for Windows」という項目に最新版・64bit用・ZIP版のダウンロードリンクボタンが用意されています。
ちなみにドロップダウンした箇所の「Windows」をクリックすると、これまでのリリース一覧が表示されます。
32bitだったり、古いバージョンが欲しい人はこちらになります。
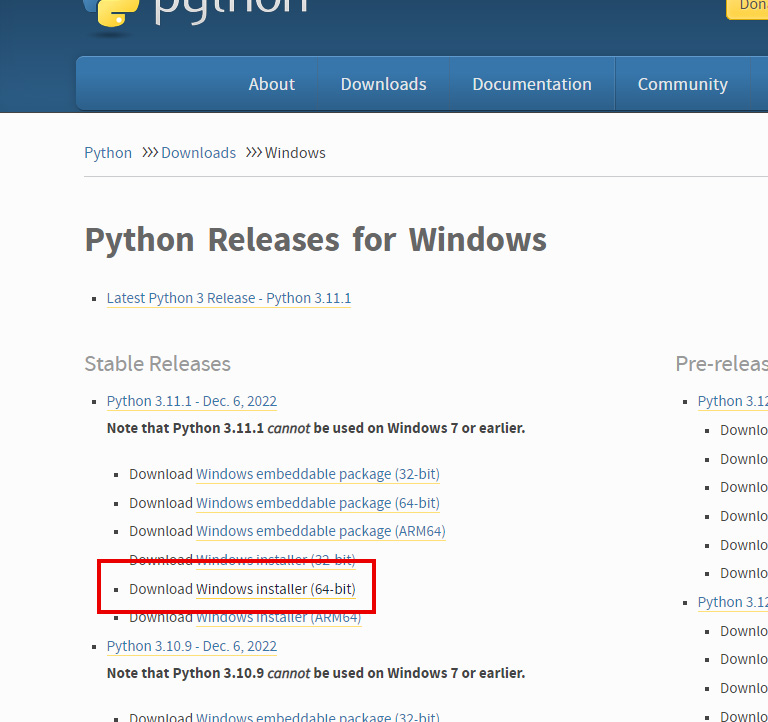
インストーラー版もこちらにありますので、俺バカだからよくわからねえんだけどよぉ!って人はインストーラー版にしましょう。私もそうした。
ZIPで落としても、どれ起動したらインストール始まるのかよくわかんねえよな。
インストーラー版なら、起動してあとはお任せするだけでOKです。
「Add python.exe to PATH」にはチェックを入れておきましょう。あとで手動で設定する部分を、インストール時点で先に設定しておいてもらえる、というものです。
あとはインストールをすすめて、完了したらCloseでOKです。
gitのインストール
gitとは、プログラミング等で使うバージョン管理システムのこと。
Aというプログラムを作ったあと、最新バージョンに更新したA_20230101【最新】を作成したとして、大元になったA自体のアーカイブも自動でしてくれる、みたいな感じ。
その後A_20230201【最新】【完全版】を作成した場合、AもA_20230101【最新】もそれぞれアーカイブされているため、新しいバグが見つかったときに前のバージョンに戻って修正をかけたり、Aをベースに今度はA’を作ったりできるわけですね。
まぁ今回はそういう使い方をしないんですが。
本インストールにおいては、gitは最新版のwebuiをインストールしてきたり、今後アプデが入ったときに最新版への更新をかけるときに使います。
こちらも無料でダウンロード可能です。
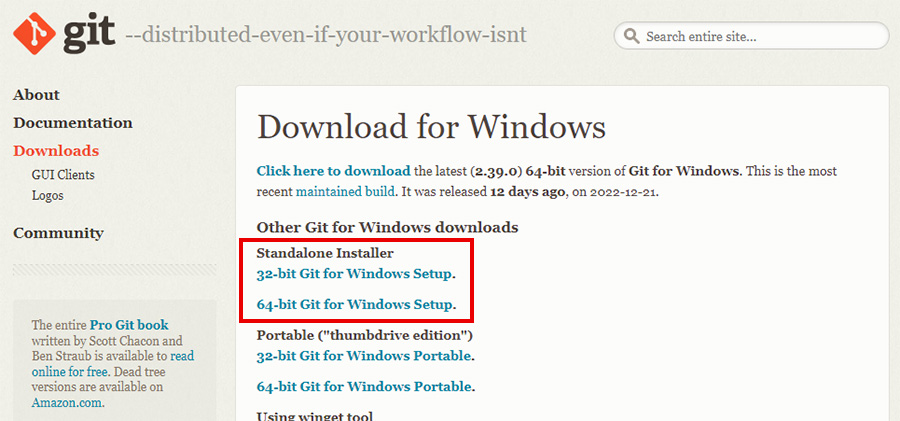
ダウンロードは公式HPであるhttps://git-scm.com/download/winから。
Standalone Installerから自分の環境に合わせたものをクリックすれば、最新版のインストーラーがダウンロードできます。
今32bitOS使ってる人っているんだろうか?
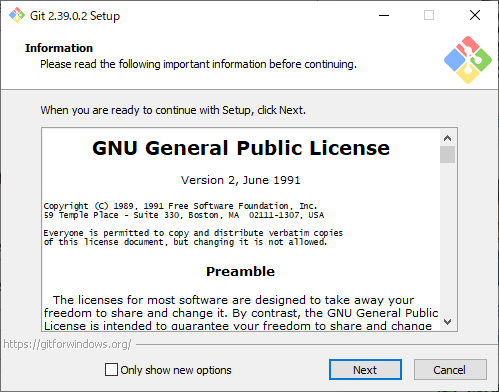
インストールを進めましょう。
大量に設定ウインドウを経由しますが、今回は全てデフォルトの選択肢でOKのはず。
チェックを入れたり外したりは一旦忘れて、インストールを進めてください。
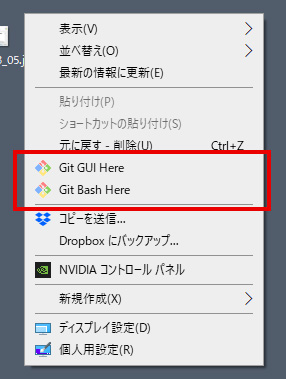
インストールが完了すると、エクスプローラー上(デスクトップとか、何かしらのフォルダ上とか)で右クリックすると、メニュー項目が増えているはず。
こうなっていたらOKです。
webuiのインストール
ここまでプログラムの環境が構築し終わったら、本体のインストールです。
webuiをインストールしたい任意の場所で右クリックし、先程増えた右クリックメニュー「Git Bash Here」をクリックします。
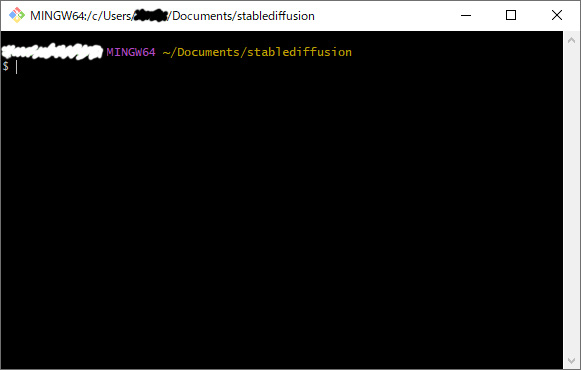
コマンドプロンプトみたいなのが起動しますので、ここに
| git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git |
|---|
と入力すると、あとはgitが全ての準備を整えてくれます。
自分の選んだ場所に「stable-diffusion-webui」というフォルダが出来ていたら完了です。
学習モデルの準備
AIが描いてくれる絵の方向性を決める、絵の学習元です。

どちらも青空の下にいる、セーラー服の女の子というPromptですが、モデルが異なっていれば、同じPromptからこれくらい違う画像が出力されるわけですね。
学習モデルは、もっぱら「Hugging Face」でダウンロードが可能。
Hugging FaceはAI向けの学習モデルやプログラムの共有プラットフォームです。
学習モデルはckptという拡張子のファイルです。
いくつか挙げておきますと
Stable Diffusion v2-1
https://huggingface.co/stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-ema-pruned.ckpt
Stable Diffusionが提供している学習モデルです。
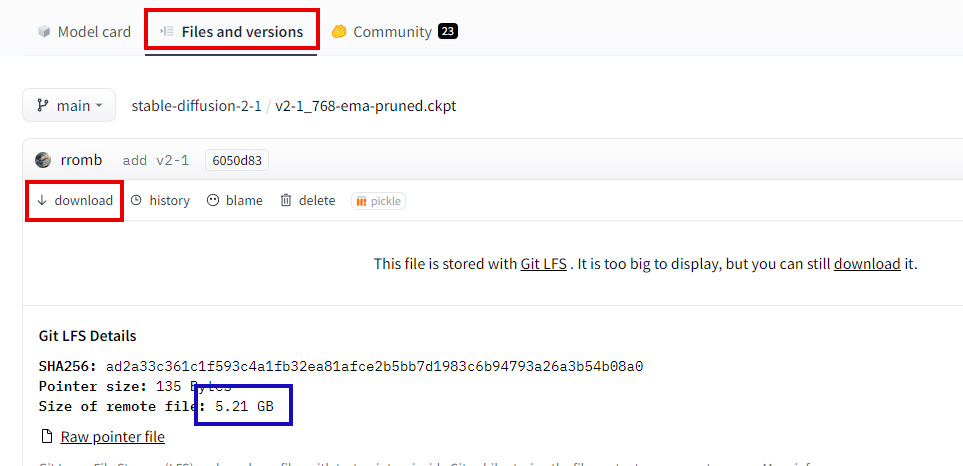
上のタブが「Files and versions」になっていることを確認しましょう。
ちなみに「Model card」にはファイルの概要が、「Community」ではこのファイルに関するコミュニケーションがスレッド形式で見られます。
青枠の「Size of remote file」ではファイルの容量が確認できます。
学習モデルはどれも容量がバカ高く、いずれも3~7GBくらいあります。
問題なければ「↓download」をクリックすると、ファイルをダウンロードできます。
Anything-v3.0
https://huggingface.co/Linaqruf/anything-v3.0/blob/main/Anything-V3.0.ckpt
出自が不明なものの、いわゆる二次元イラストへの特化モデルとして極めて性能が高く、ローカル環境で動作させる二次元絵モデルならこれを入れておけばいいレベル。
なおAny3.0はckptファイルと一緒に、
https://huggingface.co/Linaqruf/anything-v3.0/blob/main/Anything-V3.0.vae.pt
「Anything-V3.0.vae.pt」というファイルもダウンロードが必要になります。
合わせて落としておきましょう。
Trinart
https://huggingface.co/naclbit/trinart_stable_diffusion_v2/blob/main/trinart2_step115000.ckpt
AIのべりすと等で有名なAI「とりんさま」の提供しているAIイラストサービス「trinart」のモデルを無償で提供してくれているもの。
気前が良すぎる。
など。
このモデルファイルは日々誰かが作成しては共有、更にそれをマージモデルにして新しい学習モデルを開発…と日進月歩すぎる進歩を繰り広げており、この界隈から一週間目を離すと追いつけなくなっているレベル。
今書いている記事も、数カ月後には陳腐化しているかもしれませんね。
ダウンロードした学習モデルファイル(.ckptと.vae)は
| stable-diffusion-webui/models/Stable-diffusion |
|---|
に入れておけば自動で読み込んでくれます。
Stable Diffusionの起動
インストールいたフォルダ直下にある
| webui-user.bat |
|---|
をダブルクリックして起動します。
コマンドプロンプトが起動され、あとは自動的にStable Diffusionの環境が構築されます。
「webuiの」ではなく「Stable Diffusionの」環境が構築されるわけですね。
初回起動時のみですが、これが長ければ1時間レベルで時間がかかりますので、しばらくほったらかしておきましょう。
その間にご飯食べたりお風呂入ったりしましょう。

全ての準備が完了すると、Running on local URL:という項目が表示され、http://127.0.0.1:7860/というアドレスが表示されます。
これが表示されてから、ブラウザでhttp://127.0.0.1:7860/にアクセスするとStable Diffusion webuiの起動が完了します。
webuiを使ってみる
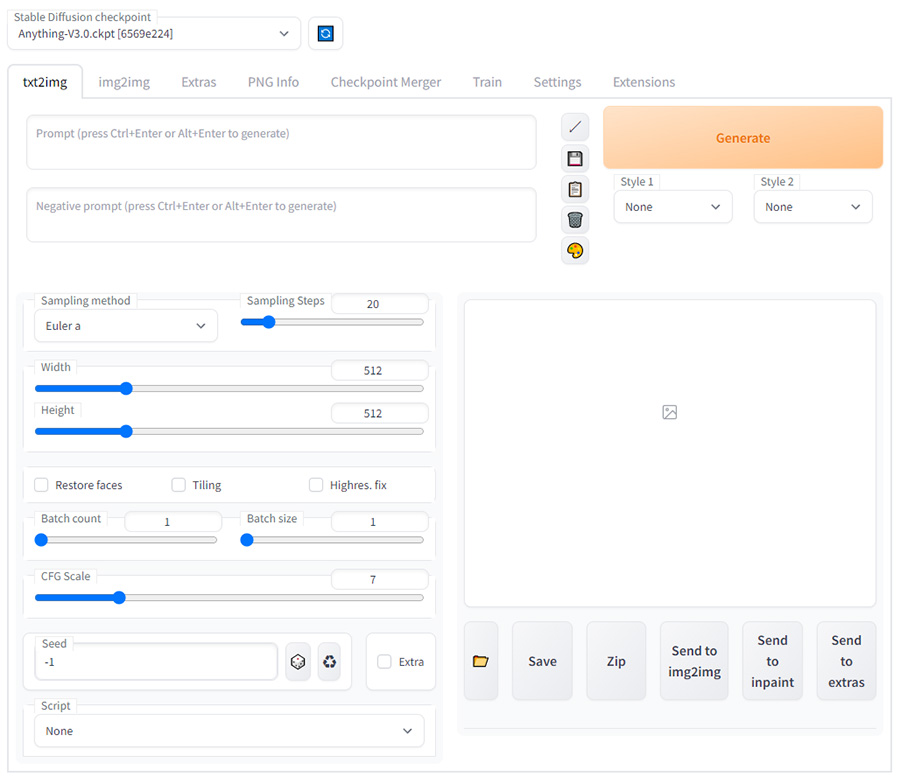
これでローカル版Stable Diffusionの導入は完了です。
普段使う項目について、ざっと説明しておくと
txt2img
テキストから画像を生成するシステム。
Promptに「1 girl, standing」とか入れると立った状態の女の子の絵が出てきたりするやつです。

今回は「1 girl, pose, black long hair, high neck swearter, skirt, black frame glasses」で、眼鏡のセーターお姉さんを描いてもらいました。
ハイネックセーター=巨乳の共通認識があるおかげか、自然と胸がでかいです。
貧乳ハイネックセーターの学習データが少なかったのでしょう。
stepsを増やすと時間がかかる代わりに精細さの増した画像が作成できるようになります。
WitdhとHeightで画像のサイズが変わりますが、私の環境だと1辺が1200pxを越えると画像生成が落ちるようになりました。
Batch countを増やすと一度に複数枚の画像が作れるようになります。
CFG ScaleはPromptの優先度で、低いとPromptをある程度無視して生成し、高めるとPromptの記述を絵の自然さよりも優先して生成します。5.5~7くらいがおすすめ。
Seedは絵を生成するにあたっての乱数で、同じPrompt、同じStep、同じサイズ、同じScaleの場合、Seedが同じなら同じ画像が生成されます。
逆に言うと、Seedが違うなら、Promptを無視しない範囲で別の画像が生成されるわけですね。
「-1」は「ランダム」という意味です。
img2img
既存の画像をベースに画像を生成するシステム。
例えば以下はHolaraで生成してもらった画像なのですが、

これをベースにして、Promptに先程の「1 girl, pose, black long hair, high neck swearter, skirt, black frame glasses」と入れると

このように大まかなレイアウトを再現しつつ、Promptで入力した情報を拾った画像にしてくれます。
img2imgの場合は「Denoising strength」というパラメータが重要になっていて、このパラメータが0に近いほど元の画像を維持し、1に近いほど元の画像の情報を無視します。
0だとマジでそのまま元の画像が表示され、

0.5だとこう。
服装、眼鏡は合っていますが、髪色は元画像の要素が残っています。

0.75でこう。
うっすらポーズの方向性が合っているだけで、元画像の要素はほぼ消えていますね。

1にすると元の画像の要素は完全に消えて、img2imgでゼロから生成したような状態です。
0.5~0.75あたりが、いい具合に元のデータを残しながらポーズやレイアウトをコントロール出来て楽しいです。
inpaint
img2img機能の一つで、画像の中の特定の箇所だけ描き直しをさせられる機能。
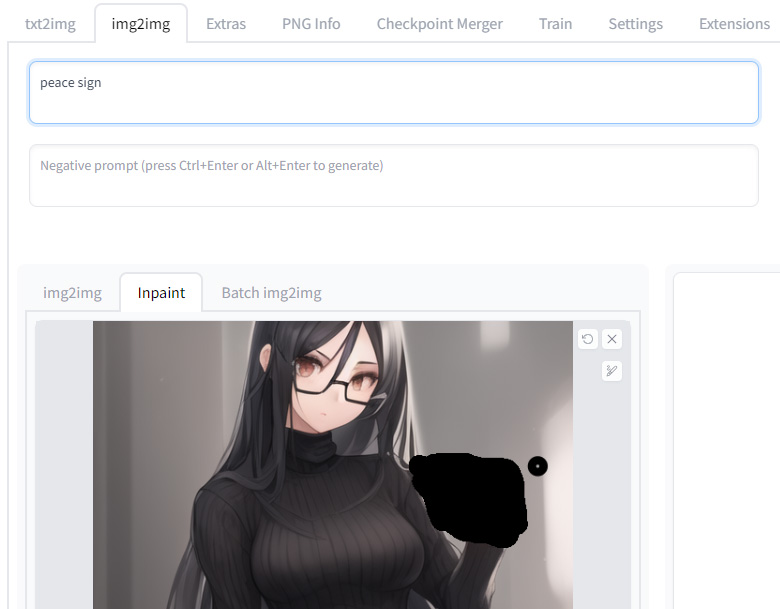
こんな感じで、最初にtxt2imgで生成した画像の手元を塗りつぶして、Promptに「peace sign」とだけ入れます。

これで出力すると、こんな感じになります。
それなりにしっかりピースサインになりましたが、塗りつぶした範囲が狭かったせいか、人差し指と中指の指先がぼやけてしまいました。
塗りつぶしはなるべく広く行うことをおすすめします。
Batch img2img
フォルダの画像を全てimg2imgさせる機能…なのだけど、使ったことがありません。
フォルダまるごとimg2imgしたいと思ったことがないから…。
Extras
画像を拡大するツールです。
AI生成の絵は、解像度を高くするとその分時間も負荷もかかるので、大きい画像が欲しいときは生成したあとに拡大することをよく勧められます。

さっき生成した眼鏡お姉さんの画像はそもそもがぼんやりした画像だったので、Holaraの作ってくれた絵で実験。
今のところ、Photoshopで拡大したものと大差ない感じ。
PNG info
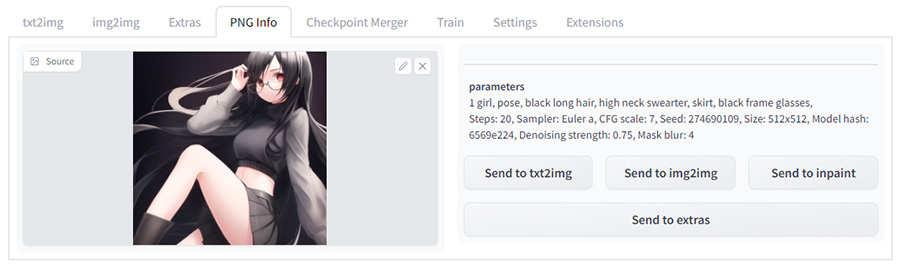
Stable Diffusionで生成した画像は、基本的にPNGとしてPromptやStep数、SEED値などの情報が記録されています。
それを閲覧し、txt2imgやimg2imgに転送することが出来ます。
ただimg2imgで生成した画像だと、参考にした画像までは記録されていませんし、画像をPhotoshopなどで加工調整して書き出し直すと、PNG情報も消去されてしまうことがあります。
自分の生成した画像のPromptをもう一度持ってきてSeed値だけ違う画像を作りたいときとか、SNSで気になる画像を見つけてPromptを拝見したいときなどに使いましょう。

というわけで、ひとまずStable Diffusion webuiの導入説明でした。
画像はPromptに悩んで不機嫌な眼鏡美人。まぁまぁ良い画像になったと思ったけど、よく見るとPC本体を睨んでモニタにそっぽ向いてるし、キーボードを反対側から叩いてるな…。
さて、AI絵はまだまだこれから伸びていく分野だと思いますし、半年後には全く別の姿になっているかもしれません。
この記事が果たしていつまで参考になるかわかりませんが、ユーザーが一人でも多く増え、環境が進む速度が更に早くなるといいなあと思っています。
コメントを残す